Pandas crosstab交叉表
交叉表:crosstab
什么是交叉表
交叉表是一种常用的分类汇总表格,用于频数分布统计,主要价值在于描述了变量间关系的深刻含义。虽然两个(或以上)变量可以是分类的或数量的,但是以都是分类的情形最为常见。
交叉表(cross-tabulation, 简称crosstab)是一种用于计算分组频率的特殊透视表。
pandas.crosstab(index,
columns,
values=None,
rownames=None,
colnames=None,
aggfunc=None,
margins=False,
margins_name: str = 'All',
dropna: bool = True,
normalize=False) → 'DataFrame'
例子中用到的数据
假设我们有两个变量,性别(男性或女性)和手性(右或左手)。 进一步假设,从非常大的人群中随机抽取100个人,作为对手性的性别差异研究的一部分。 可以创建一个交叉表来显示男性和右撇子,男性和左撇子,女性和右撇子以及女性和左撇子的个人数量。 这样的交叉表如下所示。
男性,女性以及右撇子和左撇子个体的数量称为边际总数。总计(即交叉表中所代表的个人总数)是右下角的数字。
数据来自http://Kaggle.com,是一个关于facebook的真实和虚假账号的数据集,包含了889个账户真实与否信息、好友数、教育情况、性别、等信息。数据集里有一个缺失值,进一步处理之前,先把缺失值去掉。
import pandas as pd
df = pd.read_csv('facebookac.csv')
dr = df.dropna()
df = df.replace(' ', 'not available')
用Pandas构建交叉表
基本的pandas方法
Pandas的crosstab()方法(官方文档在此)能够快速构建交叉表,并可以通过参数加以个性化的设置。其中,第一个参数将构成交叉表的行,第二个参数将构成交叉表的列。通过这个快捷的方法,我们能看到真实和虚假账户中不同情感关系状态的频数,非常清晰明了。
pd.crosstab(df['relationship'], df['Status'])

pandas的DataFrame中的另外两个用于数据汇总转换的方法——groupby()、pivot_table()——也分别都可以实现这个效果,不过会麻烦一些。DataFrame.grouby()官方文档在此,DataFrame.pivot_table()官方文档在此。
df.groupby(['relationship', 'Status'])['relationship'].count().unstack()
df.pivot_table(values='education', index='relationship',
columns='Status', aggfunc=len)
crosstab()重要参数
在交叉表中,我们常常需要统计边际总数(各行和各列的总和)。当然我们可以用sum()先算出各行、各列的和再用cancat()合并到交叉表中,不过这样实在太麻烦了。Crosstab()的参数margins可以帮我们“一键解决”,还可以通过margins_name设置总计行(列)的名称(默认名称是“All”)。
pd.crosstab(df['relationship'], df['Status'],
margins=True, margins_name='Total')

在实际应用中,我们常常需要统计交叉表中各项的相对频率(即所占百分比)。一开始,总是繁琐地先用sum()算出总和,然后用div()来求出相对相对频率。后来发现可以在crosstab()中,直接通过参数 normalize设置,方便多了。
pd.crosstab(df['relationship'], df['Status'], normalize=True)
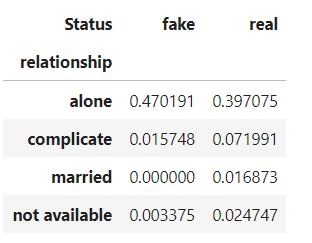
如果需要计算的是各项在所在行(列)的相对频数,normalize一样可以解决。normalize可以接受三种不同类型的参数,分别是{True, False}、{‘all’, ‘index’, ‘columns’}和 {0,1}。其中“index”或0表示按行统计(每行总和都为1),“columns”或“1”表示按列统计(每列总和都为1)。
pd.crosstab(df['relationship'], df['Status'], normalize=0)

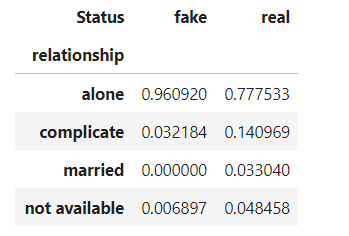
pd.crosstab(df['relationship'], df['Status'], normalize=1)
分层交叉表
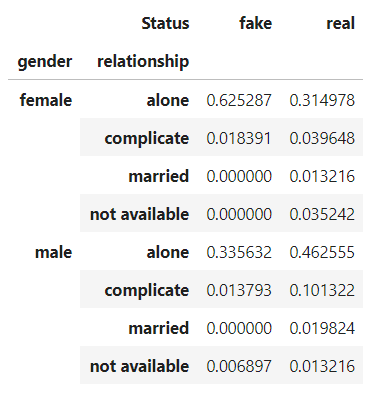
crosstab()的参数index和columns可以接受列表传入,构建分层交叉表。比如,我们在交叉表中再加入性别(表格中的“gender”列)信息,并按列计算相对频率,看看在真实和虚假账户中,不同的性别和情感关系状态和是怎么分布的。这个交叉表中,每一列的总和为1。
dfv = pd.crosstab([df['gender'], df['relationship']],
df['Status'], normalize=1)
dfv
可以按指定的列排序
dfv[['real','fake']]

交叉表可视化
看到上面的这个交叉表,大家心里可能会默默算一下哪些类型占比高,哪些类型占比低。如果数据多了,就会很难有直观感受。好在,我们有热图。Seaborn库中的heatmap()能快速生成热图,官方文档在此。
import seaborn as sns
sns.heatmap(dfv, cmap='YlOrRd', annot=True)
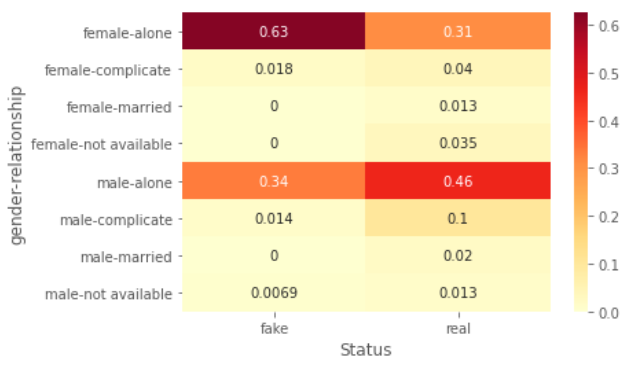
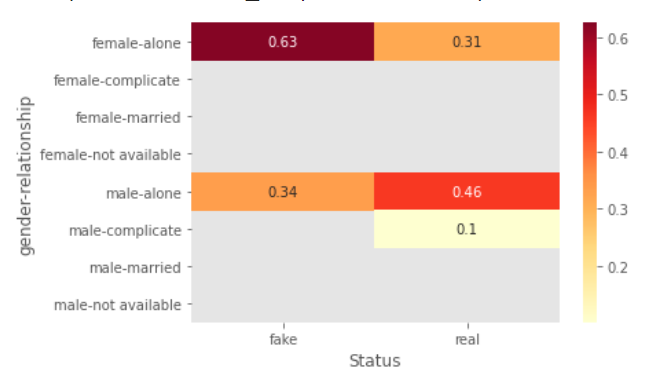
cmap='YlOrRd'是把颜色设置为:数值从低到高,颜色依次是黄色、橙色、红色。annot=True是指在热图中保留数值。可以看到,返回的热图中,每一列的把两层分组的索引值标注了出来,非常清晰。在虚假账户中,最多的是“单身女性”,其次是“单身男性”,其他的组合极少甚至没有。而真实账户中,最多的是“单身男性”,并且在各种组合中都有分布。
交叉表数据量大的时候,即使热图也会让人看不过来。这时可以通过参数mask来筛选热图中显示的数据,不符合条件的就不会显示了。这样,我们就可以更集中地关注特定的数据。比如,我们只关注占比超过10%的类型,dfv<0.1可以把小于0.1的值过滤掉。
sns.heatmap(dfv, cmap='YlOrRd', annot=True, mask=dfv<0.1)
others
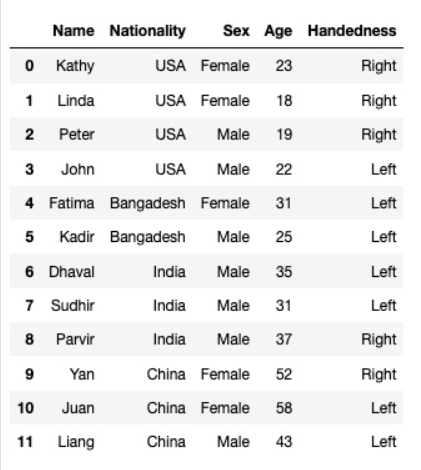
import pandas as pd
df = pd.read_excel('survey.xls')
df
pd.crosstab(df.Nationality, df.Handedness)
输出:
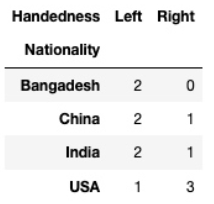
crosstab 第一个参数是列,第二个参数是行。还可以添加第三个参数:
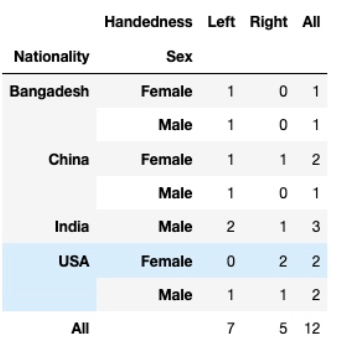
pd.crosstab(df.Sex, df.Handedness, margins = True)

pd.crosstab([df.Nationality, df.Sex], df.Handedness, margins = True)
求百分比:
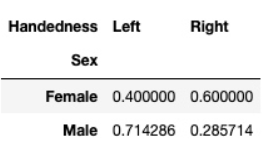
pd.crosstab(df.Sex, df.Handedness, normalize='index')
求指定列的平均值:
import numpy as np
pd.crosstab(df.Sex, df.Handedness, values=df.Age, aggfunc=np.average)

参考
Pandas 基础 (13) - Crosstab 交叉列表取值
用Python统计推断——交叉表篇(上:crosstab与热图)
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.crosstab.html